
Computer Tutors and Bloom’s 2 Sigma Problem
How far have we come in solving it?


A series of studies in the 1980s showed that the average tutored student performed better than 98% of the class. Bloom’s "2 Sigma" Problem is that most students have the potential to do incredibly well (two standard deviations above the mean), but one-to-one tutoring is too expensive for the current education system. That means we need to find ways to get the same levels of achievement through group teaching, which still hasn’t been solved today.
If you want an in-depth review of the study and its findings, here’s a better (and longer) discussion on the evidence. It basically comes down to three ideas:
The effect was probably an outlier due to small sample sizes
But there’s solid backing for at least a 1 sigma effect on Mastery Learning (constant feedback and corrections) as well as tutoring
There are even case studies that found a larger effect than Bloom. For example, the DARPA digital tutor in 2010 was used to train US Navy technicians, and resulted in students outperforming even the teachers!
Instead of covering that this week, I’m more interested in looking at how far we’ve gotten with mass tutoring 30 years down the line. Computers seem to be our best bet at solving this problem, and recently it feels like everyone and their pet GPT model are claiming they’ve cracked the code.
Intelligent Tutoring Systems
Turns out, we’ve been trying to make AI tutors since the 1970s. Intelligent Tutoring Systems are computer programs that customize teaching based on a learner’s needs.
The classic ITS is set up in four parts:
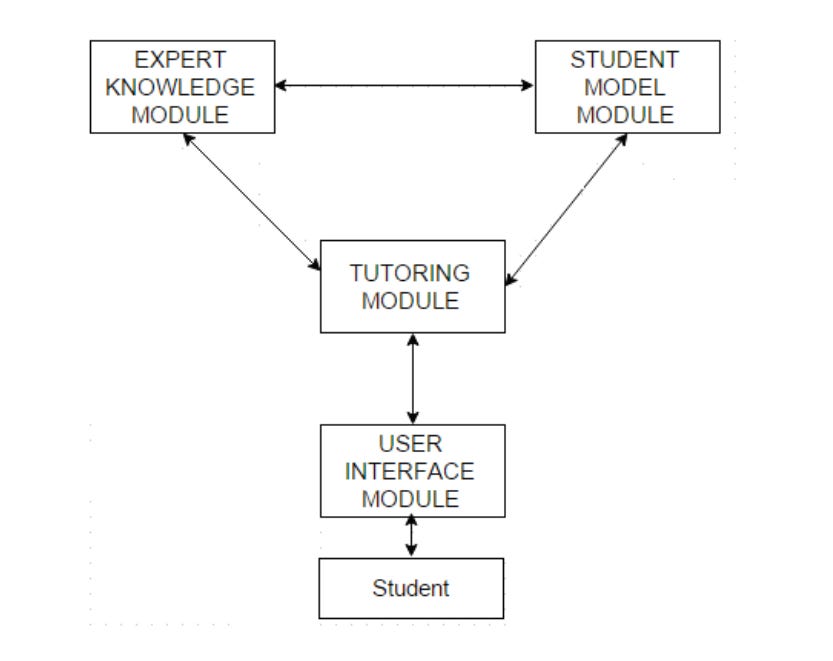
Expert module, which holds the knowledge/problem solving techniques
Student module, which tracks how the student responds to learning
Tutor module, which decides what strategies to use when fixing your problems
User interface, which is where you use the platform
The most popular AI behind this has been a simple rule-based model: based on a condition, take an action. Students tend to make the same mistakes, and when combined with the right tracking tools the program can react in real time to give hints or feedback.
The main problem has been that people have had to build a new implementation from scratch for most applications, resulting in a wide range of effectiveness.
Man Versus Machine
We’re still a long way off from software coming close to human tutors. It’s insanely hard to capture the subtlety and complexity of human teaching, and research seems to support that by showing reduced effect sizes.
Even so, we’ve already come a long way. Computers can already use the interactivity of one-on-one teaching. They give students personalized feedback and control over their own learning, making them more interested and engaged; there’s even research into adapting to student learning styles. More than 90% of studies on digital tutors find positive improvements at the 50th-75th percentile level, or 0.66 standard deviations above the mean.
More recently, machines have also been able to recognize human emotions and incorporate it into the learning process: for example, when a student is frustrated, the system can present problems similar to ones they have solved before to make them happier. There’s also development in the game direction, which could actually be more fun than traditional teaching; but making these platforms doesn’t seem to have gotten easier.
Where We Are Now
Today, we’ve got more building tools such as GIFT (Generalized Intelligent Framework for Tutoring) which give people frameworks to build adaptive online tutors, or open-source projects such as Trane which helps automate deliberate practice. Despite how far the field has come, we’re still missing a lot of the best versions of this software simply because it’s hard to find the right builders.
Implementation matters more than anything in trying to build a computer tutor: the best resources will pay off massively, while the worst might be less than useless as they take away valuable teaching time.
Students who had to share computers when using Khan Academy actually scored lower on tests, even though the opposite effect was found when the platform was used well.
The best way of framing this issue comes from the Nintil blog:
“The key difficulty is that one needs both to be a good creative problem solver, and have domain knowledge in order to translate knowledge and explanations into good software. Many are developed by PhD students and then abandoned. Even the DARPA tutor doesn't seem to have been put into production yet, for some reason.”
The rise of online learning platforms such as Brilliant or Khan Academy over the last few years gives us some hope. Maybe soon someone will create a meta-platform to collect these problem solvers in one place and fund them. Right now, to even get started making a good tutor requires a rare blend of computer science, psychology, and educational research: you probably wouldn’t even know if anyone would use it.
This is also why I’m a bit skeptical of any Large Language Model-based online tutor: they don’t seem to be addressing the key challenge with software so far, which is carefully curating content and packaging it to work well online.
We should be focusing on the strengths of digital tutoring by building platforms that are actually easy to use, both for teachers and students.
The technology is out there, we just need the people.
Thanks for reading! You’ll find some interesting sources below:
2018, Journal Impact Factor - 5.22
Intelligent Tutoring Systems: A Comprehensive Historical Survey with Recent Developments
2018, Journal Impact Factor - 1.1
Intelligent tutoring systems for programming education: a systematic review
2018, Conference paper - 68 citations